class: title-slide, bottom, right background-image: url(https://images.unsplash.com/photo-1542320260-f8f651de8c12?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=1170&q=80) background-size: cover ### Data wrangling # ### **Miriam Lerma**<br> May 2023 --- name: index class: title-slide, inverse # Index - [rmarkdown](#rmd) - [read files](#read-files) - [basic operations](#basic-operations) - [columns and rows](#column-rows) - [tidydata](#tidydata) - [distinct](#distinct) - [count](#count) - [select](#select) - [filter](#filter) - [mutate](#mutate) - [summarise](#sumarise) - [drop_na](#drop) - [join](#join) - [export](#export) - [contact](#out) --- class: title-slide, inverse # Today .pull-left[ **Your profile** - You have R and Rstudio installed - You can navigate inside Rstudio **Goals of today** - Difference between R script and Rmd - Load data - Basic operations - Manipulate data - Export clean data **Pauses and questions** - Exercises and 10 minute pauses for catching up - You can stop me to ask questions or use [this link <svg aria-hidden="true" role="img" viewBox="0 0 512 512" style="height:1em;width:1em;vertical-align:-0.125em;margin-left:auto;margin-right:auto;font-size:inherit;fill:#f2cc8f;overflow:visible;position:relative;"><path d="M432,320H400a16,16,0,0,0-16,16V448H64V128H208a16,16,0,0,0,16-16V80a16,16,0,0,0-16-16H48A48,48,0,0,0,0,112V464a48,48,0,0,0,48,48H400a48,48,0,0,0,48-48V336A16,16,0,0,0,432,320ZM488,0h-128c-21.37,0-32.05,25.91-17,41l35.73,35.73L135,320.37a24,24,0,0,0,0,34L157.67,377a24,24,0,0,0,34,0L435.28,133.32,471,169c15,15,41,4.5,41-17V24A24,24,0,0,0,488,0Z"/></svg>]( https://docs.google.com/document/d/1uG7a2_hkdaKQm5gKXRBFf6gcyoUBan2e69gL3ZKcwg8/edit?usp=sharing) ] -- .pull-right[ <img src="https://github.com/MiriamLL/R_intro/blob/master/Images/101AllisonHorstREncouraging.png?raw=true" height="400" /> ] --- class: title-slide, inverse # References - R for Data Science [<svg aria-hidden="true" role="img" viewBox="0 0 576 512" style="height:1em;width:1.12em;vertical-align:-0.125em;margin-left:auto;margin-right:auto;font-size:inherit;fill:#f2cc8f;overflow:visible;position:relative;"><path d="M542.22 32.05c-54.8 3.11-163.72 14.43-230.96 55.59-4.64 2.84-7.27 7.89-7.27 13.17v363.87c0 11.55 12.63 18.85 23.28 13.49 69.18-34.82 169.23-44.32 218.7-46.92 16.89-.89 30.02-14.43 30.02-30.66V62.75c.01-17.71-15.35-31.74-33.77-30.7zM264.73 87.64C197.5 46.48 88.58 35.17 33.78 32.05 15.36 31.01 0 45.04 0 62.75V400.6c0 16.24 13.13 29.78 30.02 30.66 49.49 2.6 149.59 12.11 218.77 46.95 10.62 5.35 23.21-1.94 23.21-13.46V100.63c0-5.29-2.62-10.14-7.27-12.99z"/></svg> R4DS](https://r4ds.had.co.nz/) - Data Carpentries [<svg aria-hidden="true" role="img" viewBox="0 0 576 512" style="height:1em;width:1.12em;vertical-align:-0.125em;margin-left:auto;margin-right:auto;font-size:inherit;fill:#f2cc8f;overflow:visible;position:relative;"><path d="M542.22 32.05c-54.8 3.11-163.72 14.43-230.96 55.59-4.64 2.84-7.27 7.89-7.27 13.17v363.87c0 11.55 12.63 18.85 23.28 13.49 69.18-34.82 169.23-44.32 218.7-46.92 16.89-.89 30.02-14.43 30.02-30.66V62.75c.01-17.71-15.35-31.74-33.77-30.7zM264.73 87.64C197.5 46.48 88.58 35.17 33.78 32.05 15.36 31.01 0 45.04 0 62.75V400.6c0 16.24 13.13 29.78 30.02 30.66 49.49 2.6 149.59 12.11 218.77 46.95 10.62 5.35 23.21-1.94 23.21-13.46V100.63c0-5.29-2.62-10.14-7.27-12.99z"/></svg> Carpentries](https://datacarpentry.org/genomics-r-intro/00-introduction/index.html) - R cookbook [<svg aria-hidden="true" role="img" viewBox="0 0 576 512" style="height:1em;width:1.12em;vertical-align:-0.125em;margin-left:auto;margin-right:auto;font-size:inherit;fill:#f2cc8f;overflow:visible;position:relative;"><path d="M542.22 32.05c-54.8 3.11-163.72 14.43-230.96 55.59-4.64 2.84-7.27 7.89-7.27 13.17v363.87c0 11.55 12.63 18.85 23.28 13.49 69.18-34.82 169.23-44.32 218.7-46.92 16.89-.89 30.02-14.43 30.02-30.66V62.75c.01-17.71-15.35-31.74-33.77-30.7zM264.73 87.64C197.5 46.48 88.58 35.17 33.78 32.05 15.36 31.01 0 45.04 0 62.75V400.6c0 16.24 13.13 29.78 30.02 30.66 49.49 2.6 149.59 12.11 218.77 46.95 10.62 5.35 23.21-1.94 23.21-13.46V100.63c0-5.29-2.62-10.14-7.27-12.99z"/></svg> R cookbook](http://www.cookbook-r.com/) - From Zero to Shero by RLadies [<svg aria-hidden="true" role="img" viewBox="0 0 480 512" style="height:1em;width:0.94em;vertical-align:-0.125em;margin-left:auto;margin-right:auto;font-size:inherit;fill:#f2cc8f;overflow:visible;position:relative;"><path d="M186.1 328.7c0 20.9-10.9 55.1-36.7 55.1s-36.7-34.2-36.7-55.1 10.9-55.1 36.7-55.1 36.7 34.2 36.7 55.1zM480 278.2c0 31.9-3.2 65.7-17.5 95-37.9 76.6-142.1 74.8-216.7 74.8-75.8 0-186.2 2.7-225.6-74.8-14.6-29-20.2-63.1-20.2-95 0-41.9 13.9-81.5 41.5-113.6-5.2-15.8-7.7-32.4-7.7-48.8 0-21.5 4.9-32.3 14.6-51.8 45.3 0 74.3 9 108.8 36 29-6.9 58.8-10 88.7-10 27 0 54.2 2.9 80.4 9.2 34-26.7 63-35.2 107.8-35.2 9.8 19.5 14.6 30.3 14.6 51.8 0 16.4-2.6 32.7-7.7 48.2 27.5 32.4 39 72.3 39 114.2zm-64.3 50.5c0-43.9-26.7-82.6-73.5-82.6-18.9 0-37 3.4-56 6-14.9 2.3-29.8 3.2-45.1 3.2-15.2 0-30.1-.9-45.1-3.2-18.7-2.6-37-6-56-6-46.8 0-73.5 38.7-73.5 82.6 0 87.8 80.4 101.3 150.4 101.3h48.2c70.3 0 150.6-13.4 150.6-101.3zm-82.6-55.1c-25.8 0-36.7 34.2-36.7 55.1s10.9 55.1 36.7 55.1 36.7-34.2 36.7-55.1-10.9-55.1-36.7-55.1z"/></svg> Zero to Hero](https://github.com/rladies/meetup-presentations_freiburg) - Images from [<svg aria-hidden="true" role="img" viewBox="0 0 512 512" style="height:1em;width:1em;vertical-align:-0.125em;margin-left:auto;margin-right:auto;font-size:inherit;fill:#f2cc8f;overflow:visible;position:relative;"><path d="M48 32C21.5 32 0 53.5 0 80v352c0 26.5 21.5 48 48 48h416c26.5 0 48-21.5 48-48V80c0-26.5-21.5-48-48-48H48zm0 32h106c3.3 0 6 2.7 6 6v20c0 3.3-2.7 6-6 6H38c-3.3 0-6-2.7-6-6V80c0-8.8 7.2-16 16-16zm426 96H38c-3.3 0-6-2.7-6-6v-36c0-3.3 2.7-6 6-6h138l30.2-45.3c1.1-1.7 3-2.7 5-2.7H464c8.8 0 16 7.2 16 16v74c0 3.3-2.7 6-6 6zM256 424c-66.2 0-120-53.8-120-120s53.8-120 120-120 120 53.8 120 120-53.8 120-120 120zm0-208c-48.5 0-88 39.5-88 88s39.5 88 88 88 88-39.5 88-88-39.5-88-88-88zm-48 104c-8.8 0-16-7.2-16-16 0-35.3 28.7-64 64-64 8.8 0 16 7.2 16 16s-7.2 16-16 16c-17.6 0-32 14.4-32 32 0 8.8-7.2 16-16 16z"/></svg> Unsplash](https://unsplash.com/) [<svg aria-hidden="true" role="img" viewBox="0 0 512 512" style="height:1em;width:1em;vertical-align:-0.125em;margin-left:auto;margin-right:auto;font-size:inherit;fill:#f2cc8f;overflow:visible;position:relative;"><path d="M204.3 5C104.9 24.4 24.8 104.3 5.2 203.4c-37 187 131.7 326.4 258.8 306.7 41.2-6.4 61.4-54.6 42.5-91.7-23.1-45.4 9.9-98.4 60.9-98.4h79.7c35.8 0 64.8-29.6 64.9-65.3C511.5 97.1 368.1-26.9 204.3 5zM96 320c-17.7 0-32-14.3-32-32s14.3-32 32-32 32 14.3 32 32-14.3 32-32 32zm32-128c-17.7 0-32-14.3-32-32s14.3-32 32-32 32 14.3 32 32-14.3 32-32 32zm128-64c-17.7 0-32-14.3-32-32s14.3-32 32-32 32 14.3 32 32-14.3 32-32 32zm128 64c-17.7 0-32-14.3-32-32s14.3-32 32-32 32 14.3 32 32-14.3 32-32 32z"/></svg> Allison horst](https://allisonhorst.com/allison-horst) --- name: rmd class: title-slide, inverse, bottom background-image: url(https://images.unsplash.com/photo-1542319785-59a73ea1c114?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=1170&q=80) background-size: cover .pull-right[ # <span style=" font-weight: bold; color: #e5e5e5 !important;border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #003049 !important;" >R markdown</span> ### <span style=" font-weight: bold; color: #e5e5e5 !important;border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #003049 !important;" >Parts of the kitchen</span> ] --- ## 1. RMarkdown Rmarkdown is very convenient because it let us export what we do in R to html or word documents. We can even make slides... <br> .right[...like this one.] -- There are **plenty** of options on Rmd. I will just point out a few. --- ## 1.2. Rmd Markdown is plain text... .right[...just as we write in a note block.] However, the advantages of using Rmd is that you can include a lot of text and thus you can write your **thesis, papers, webpage, books and presentations** without leaving RStudio. -- Moreover, you can include: - code and results that are automatically generated. --- ## 1.2. Rmd What Rmd does, is that it "translates" what has been written using **PanDoc**. .center[ <img src="https://d33wubrfki0l68.cloudfront.net/61d189fd9cdf955058415d3e1b28dd60e1bd7c9b/b739c/lesson-images/rmarkdownflow.png" width="600" /> ] --- ## 1.2. Rmd We can generate an **output**, that can be read even if you dont have R install. Just like this presentation. -- Also, you can get your results without showing the code and without having to copy and paste the results in other program like word. - Download Rmd file [here](https://raw.githubusercontent.com/MiriamLL/R_intro/master/02ExercisesRmd.Rmd). See the example: _List of ingredients_ ```r ingredients<-c('tomatoes','onions','pepper','salt','oil') length(ingredients) ``` ``` ## [1] 5 ``` --- ## 1.2. R vs Rmd **Considerations: ** Rmd behaves differently than R - Rmarkdown works better in a clean environment. - All the variables need to be inside your file. - This actually assures that your workflow is **reproducible**. --- ## 1.3. Start an Rmd To start a new file File>NewFile>RMarkdown <br> <img src="https://github.com/MiriamLL/R_intro/blob/master/Images/040Rmd.png?raw=true" height="300" /> --- ## 1.4. Rmd parts Rmd has four main parts: - yaml (including the output) - chunks - plain text - knit <img src="https://github.com/MiriamLL/R_intro/blob/master/Images/041Rmd.png?raw=true" height="300" /> --- ## 1.5. Rmd text You can write plain text in the white area You can use: - **bold** using two astheriscs. - *italics* using one astherics before and one after the word. <img src="https://github.com/MiriamLL/R_intro/blob/master/Images/042RmdPlainText.png?raw=true" height="300" /> More options: [<svg aria-hidden="true" role="img" viewBox="0 0 512 512" style="height:1em;width:1em;vertical-align:-0.125em;margin-left:auto;margin-right:auto;font-size:inherit;fill:#e9c46a;overflow:visible;position:relative;"><path d="M432,320H400a16,16,0,0,0-16,16V448H64V128H208a16,16,0,0,0,16-16V80a16,16,0,0,0-16-16H48A48,48,0,0,0,0,112V464a48,48,0,0,0,48,48H400a48,48,0,0,0,48-48V336A16,16,0,0,0,432,320ZM488,0h-128c-21.37,0-32.05,25.91-17,41l35.73,35.73L135,320.37a24,24,0,0,0,0,34L157.67,377a24,24,0,0,0,34,0L435.28,133.32,471,169c15,15,41,4.5,41-17V24A24,24,0,0,0,488,0Z"/></svg>Text in Rmd](https://rmarkdown.rstudio.com/lesson-8.html) --- ## 1.6. Rmd chunk The parts that are in grey are chunks. - The code is written inside three inverted commas at the start and at the end and the r between {} This is because we need to tell which language are we using - We can run the code using the green arrow that looks like a <svg aria-hidden="true" role="img" viewBox="0 0 448 512" style="height:1em;width:0.88em;vertical-align:-0.125em;margin-left:auto;margin-right:auto;font-size:inherit;fill:#588157;overflow:visible;position:relative;"><path d="M424.4 214.7L72.4 6.6C43.8-10.3 0 6.1 0 47.9V464c0 37.5 40.7 60.1 72.4 41.3l352-208c31.4-18.5 31.5-64.1 0-82.6z"/></svg>, using the button **Run** in the upper part of the code editor, or using **ctrl+enter**. - The results in Rmd appears in the code editor document, not in the console. <img src="https://github.com/MiriamLL/R_intro/blob/master/Images/042RmdChunk.png?raw=true" height="300" /> --- ## 1.7. Rmd chunk We can add new code chunks using **Ctrl+Alt+I** , the **back ticks** or in the green square with a C in the upper part of the code editor **+**. The R code needs to be inside the chunks (the shadowed grey parts) to run. **Common mistakes are**: - Not closing the parenthesis **{}** - Not having the three inverted commas - Add code outside the codechunks --- ## 1.8. YAML YAML means _“YAML Yet Ain’t Markup Language”._ By default it will show: title, author, date, **output**. <img src="https://github.com/MiriamLL/R_intro/blob/master/Images/042RmdYaml.png?raw=true" height="300" /> --- ## 1.8. YAML When you change the YAML, the information that appears in your report will change<br> If you chnge the output, different type of reports will be generated. **Common mistakes** When you **knit** or render your report, there is something incompatible with Pandoc (or LateX) <img src="https://github.com/MiriamLL/R_intro/blob/master/Images/042RmdYaml.png?raw=true" height="300" /> --- ## 1.9. Knitr There is a botton that says **knit** with a knitting blue ball. This bottons generates the report. <img src="https://github.com/MiriamLL/R_intro/blob/master/Images/042RmdKnit.png?raw=true" height="300" /> **Note**: every time we knit the changes are saved on our document. --- ## 1.10. Rmd titles .pull-left[ You can use the titles to navigate. Search for the square with lines (say outline) or click on **Crtl+Shft+O**. This can be very useful in large documents. <img src="https://github.com/MiriamLL/R_intro/blob/master/Images/043Outline.png?raw=true" height="30" /> ] .pull-right[ Main title use one hashtag #.<br> - First level #.<br> - Second level ##.<br> - Third level ###.<br> <img src="https://github.com/MiriamLL/R_intro/blob/master/Images/044Outline.png?raw=true" height="100" /> ] --- name: outputs ## 1.11. Rmd outputs The documents can be exported to word, pdf and html. Advantages and disadvantages for each one: - **word**: easier to share and many journals ask for documents in this format - **pdf**: easier to share but not easy to edit - **html**: you can include a lot of type of contents ⭐, but might look unfamiliar --- ## 1.11. Rmd outputs To change the output, you need to change it in the YAML, or chick on the arrow <svg aria-hidden="true" role="img" viewBox="0 0 320 512" style="height:1em;width:0.62em;vertical-align:-0.125em;margin-left:auto;margin-right:auto;font-size:inherit;fill:#2a9d8f;overflow:visible;position:relative;"><path d="M41 288h238c21.4 0 32.1 25.9 17 41L177 448c-9.4 9.4-24.6 9.4-33.9 0L24 329c-15.1-15.1-4.4-41 17-41z"/></svg> in the knit button and chose your format. <img src="https://github.com/MiriamLL/R_intro/blob/master/Images/045Outputs.png?raw=true" height="150" /> To modify the word format [see here](https://rfortherestofus.com/2020/07/word-reference-documents-rmarkdown/) --- class: inverse # Pause - Open RStudio <svg aria-hidden="true" role="img" viewBox="0 0 512 512" style="height:1em;width:1em;vertical-align:-0.125em;margin-left:auto;margin-right:auto;font-size:inherit;fill:#FFFFFF;overflow:visible;position:relative;"><path d="M497.9 142.1l-46.1 46.1c-4.7 4.7-12.3 4.7-17 0l-111-111c-4.7-4.7-4.7-12.3 0-17l46.1-46.1c18.7-18.7 49.1-18.7 67.9 0l60.1 60.1c18.8 18.7 18.8 49.1 0 67.9zM284.2 99.8L21.6 362.4.4 483.9c-2.9 16.4 11.4 30.6 27.8 27.8l121.5-21.3 262.6-262.6c4.7-4.7 4.7-12.3 0-17l-111-111c-4.8-4.7-12.4-4.7-17.1 0zM124.1 339.9c-5.5-5.5-5.5-14.3 0-19.8l154-154c5.5-5.5 14.3-5.5 19.8 0s5.5 14.3 0 19.8l-154 154c-5.5 5.5-14.3 5.5-19.8 0zM88 424h48v36.3l-64.5 11.3-31.1-31.1L51.7 376H88v48z"/></svg> - Open a Rmd file (File>NewFile>Rmd) - Create three different formats: pdf, word and html - Delete everything except for the YAML (change YAML to your info) - Add a code chunk - Add text Example of code chunk ```r ingredients<-c('tomatoes','onions','pepper','salt','oil') length(ingredients) ``` **Note**<br> Maybe you need to install tinytex<br> ```r tinytex::install_tinytex() ``` - [<svg aria-hidden="true" role="img" viewBox="0 0 512 512" style="height:1em;width:1em;vertical-align:-0.125em;margin-left:auto;margin-right:auto;font-size:inherit;fill:#e9c46a;overflow:visible;position:relative;"><path d="M432,320H400a16,16,0,0,0-16,16V448H64V128H208a16,16,0,0,0,16-16V80a16,16,0,0,0-16-16H48A48,48,0,0,0,0,112V464a48,48,0,0,0,48,48H400a48,48,0,0,0,48-48V336A16,16,0,0,0,432,320ZM488,0h-128c-21.37,0-32.05,25.91-17,41l35.73,35.73L135,320.37a24,24,0,0,0,0,34L157.67,377a24,24,0,0,0,34,0L435.28,133.32,471,169c15,15,41,4.5,41-17V24A24,24,0,0,0,488,0Z"/></svg>What is tiny text?](https://yihui.org/tinytex/) --- name: read-files class: title-slide, bottom background-image: url(https://images.unsplash.com/photo-1495461199391-8c39ab674295?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=1170&q=80) background-size: cover .pull-right[ # <span style=" font-weight: bold; color: #e5e5e5 !important;border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #003049 !important;" >Load data</span> ### <span style=" font-weight: bold; color: #e5e5e5 !important;border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #003049 !important;" >Bring the ingredients</span> ] --- ## 2. Import A typical R project looks like this: <img src="https://github.com/MiriamLL/R_intro/blob/master/Images/031Program.png?raw=true" height="200" /> .right[ Source: [R4DS](https://r4ds.had.co.nz/introduction.html) ] --- ## 2.1. Read files To load data, we will use functions from the package tidyverse and the files: - penguins1.csv - penguins2.csv - penguins3.txt - penguins4.xlsx [Download here](https://github.com/MiriamLL/R_intro/tree/master/Downloads) Do you already have it installed? ```r library("tidyverse") ``` --- ## 2.2. By hand You can upload data by hand in your workspace In the **environment** there is a part that says **Import Dataset** Select the file **penguins1.csv** -- Another option is to go to the **workspace** Files> Click on the file and **import data set** <img src="https://github.com/MiriamLL/R_intro/blob/master/Images/019Rparts.png?raw=true" height="350" /> --- ## 2.3. csv format Instead of clicks, we can write in the console or script: ```r penguins1<-read_csv("Downloads/penguins1.csv") ``` ```r head(penguins1) ``` --- ## 2.4. csv format Now try opening **penguins2.csv** This file instead of being separated by comas, its separated by colons ";" Therefore, instead of using **read_csv** we will need to use **read_csv2** To illustrate this issue, try loading the data using **read_csv**. ```r penguins2<-read_csv("Downloads/penguins2.csv") ``` ```r head(penguins2) ``` -- Lets try now with **read_csv2** ```r penguins2<-read_csv2("Downloads/penguins2.csv") ``` ```r head(penguins2) ``` --- ## 2.5. Other formats Click on the file **penguin3.txt**. This one is separated by tabs. read_tsv is for reading tab separated values. ```r penguins3<-read_tsv("Downloads/penguins3.txt") ``` ```r head(penguins3) ``` --- ## 2.6. Excel format For loading excel data, there is a special package called **readxl** ```r library("readxl") ``` ```r penguins4<- read_excel("Downloads/penguins4.xlsx") ``` ```r head(penguins4) ``` --- ## 2.7. From an url Urls (Uniform Resource Locators) or links can also be source of data. ```r penguins5<- read_csv('https://raw.githubusercontent.com/MiriamLL/R_intro/master/Downloads/penguins1.csv') ``` Look at the first 5 rows of the data ```r head(penguins,5) ``` --- ## 2.8. movebank There is a package called [move](https://cran.r-project.org/web/packages/move/vignettes/browseMovebank.html) that can be use to access data stored in movebank. To install: ```r install.packages('move') ``` ```r library(move) ``` ```r movebankLogin() ``` Add your login, if you have one, at the console. --- ## 2.9. movebank It is more convenient to store your login information, but you have to be careful to not share the script with your login information. ```r loginStored <- movebankLogin(username="MiriamLerma", password="********") ``` ```r my_study<-'FTZ UCN Kelp Gull Chile' ``` ```r MyGull<-getMovebankLocationData(study=my_study, individual_local_identifier="KEGU-noband01-Coquimbo", timestamp_start="202212010000000", timestamp_end="20221205000000000", sensorID="GPS") ``` It might give you a warning, but for now that is not important. --- ## 2.10. packages with data Data can also be stored in packages. For example [palmerpenguins](https://allisonhorst.github.io/palmerpenguins/) ```r install.packages("palmerpenguins") ``` ```r library(palmerpenguins) penguin6<-penguins ``` ```r head(penguin6) ``` --- ## 2.11. packages with data Moreover, packages with data are not limited to data frames. --- ## 2.12. packages with data For example, the package GermanNorthSea contains shapefiles With 6 lines of code you can plot a map (Showing just for illustration purposes) .pull-left[ ```r # install.packages("devtools") devtools::install_github("MiriamLL/GermanNorthSea") ``` Now the package sf ```r #install.packages('sf') library(sf) library(ggplot2) library(GermanNorthSea) ``` Load and plot some data ```r German_land<-GermanNorthSea::German_land ``` ] .pull-right[ ```r ggplot()+ geom_sf(data = German_land, colour = 'black', fill = '#ffffbe')+ coord_sf(xlim = c(3790000,4250000), ylim = c(3350000,3680000), label_axes = list(top = "E", left = "N", bottom = 'E', right='N')) ``` 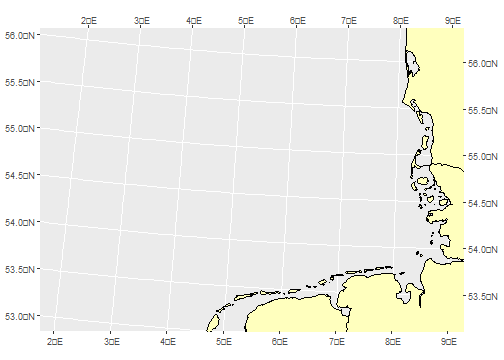<!-- --> ] --- class: inverse # Pause .pull-left[ Load penguin data <svg aria-hidden="true" role="img" viewBox="0 0 512 512" style="height:1em;width:1em;vertical-align:-0.125em;margin-left:auto;margin-right:auto;font-size:inherit;fill:#FFFFFF;overflow:visible;position:relative;"><path d="M497.9 142.1l-46.1 46.1c-4.7 4.7-12.3 4.7-17 0l-111-111c-4.7-4.7-4.7-12.3 0-17l46.1-46.1c18.7-18.7 49.1-18.7 67.9 0l60.1 60.1c18.8 18.7 18.8 49.1 0 67.9zM284.2 99.8L21.6 362.4.4 483.9c-2.9 16.4 11.4 30.6 27.8 27.8l121.5-21.3 262.6-262.6c4.7-4.7 4.7-12.3 0-17l-111-111c-4.8-4.7-12.4-4.7-17.1 0zM124.1 339.9c-5.5-5.5-5.5-14.3 0-19.8l154-154c5.5-5.5 14.3-5.5 19.8 0s5.5 14.3 0 19.8l-154 154c-5.5 5.5-14.3 5.5-19.8 0zM88 424h48v36.3l-64.5 11.3-31.1-31.1L51.7 376H88v48z"/></svg> - Using read_csv <br> - Using read_csv2 <br> - Using read_tsv <br> - Using read_excel <br> There are many other options of files. Suggestions? [here <svg aria-hidden="true" role="img" viewBox="0 0 512 512" style="height:1em;width:1em;vertical-align:-0.125em;margin-left:auto;margin-right:auto;font-size:inherit;fill:#f2cc8f;overflow:visible;position:relative;"><path d="M432,320H400a16,16,0,0,0-16,16V448H64V128H208a16,16,0,0,0,16-16V80a16,16,0,0,0-16-16H48A48,48,0,0,0,0,112V464a48,48,0,0,0,48,48H400a48,48,0,0,0,48-48V336A16,16,0,0,0,432,320ZM488,0h-128c-21.37,0-32.05,25.91-17,41l35.73,35.73L135,320.37a24,24,0,0,0,0,34L157.67,377a24,24,0,0,0,34,0L435.28,133.32,471,169c15,15,41,4.5,41-17V24A24,24,0,0,0,488,0Z"/></svg>]( https://docs.google.com/document/d/1uG7a2_hkdaKQm5gKXRBFf6gcyoUBan2e69gL3ZKcwg8/edit?usp=sharing) ] .pull-right[ Until here: - [rmarkdown](#rmd) - [read files](#read-files) Next part: - [basic operations](#basic-operationr) - [columns and rows](#column-rows) - [count](#count) - [distinct](#distinct) - [select](#select) - [filter](#filter) - [mutate](#mutate) - [summarise](#sumarise) - [drop_na](#drop) - [join](#join) - [export](#export) - [contact](#out) ] --- name: basic-operations class: title-slide, bottom background-image: url(https://images.unsplash.com/photo-1452251889946-8ff5ea7b27ab?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=799&q=80) background-size: cover .pull-right[ # <span style=" font-weight: bold; color: #e5e5e5 !important;border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #003049 !important;" >Operations</span> ## <span style=" font-weight: bold; color: #e5e5e5 !important;border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #003049 !important;" >Kitchen utensils</span> ] --- ## 3. Basic operations Add ```r 15+6 ``` ``` ## [1] 21 ``` Subtract ```r 4-6 ``` ``` ## [1] -2 ``` --- ## 3. Basic operations Divide ```r 1700/8 ``` ``` ## [1] 212.5 ``` Multiply ```r 20*20 ``` ``` ## [1] 400 ``` --- ## 3.1. Using objects .center[ <h3> ¿ 🍕 = 😃 ?</h3> ] How many people are here today? ```r People<-4+5+1 Pizza<-5*8 ``` How many pieces each one gets? ```r Pizza/People ``` ``` ## [1] 4 ``` --- ## 3.2. Using objects Mean ```r cooking_temp<-c(134,145,167,200) mean(cooking_temp) ``` ``` ## [1] 161.5 ``` Median ```r median(cooking_temp) ``` ``` ## [1] 156 ``` Standard deviation ```r sd(cooking_temp) ``` ``` ## [1] 29.10326 ``` --- ## 3.2. Using objects Range ```r range(cooking_temp) ``` ``` ## [1] 134 200 ``` Minimum ```r min(cooking_temp) ``` ``` ## [1] 134 ``` Maximum ```r max(cooking_temp) ``` ``` ## [1] 200 ``` --- ## 3.3. Look for help ```r mean(1,3,6,9,12) ``` ``` ## [1] 1 ``` Why 1? That can't be -- Ask for help using **?** ```r ?mean ``` The instructions will appear in the **workspace**, in the **Help** section See in the examples, they all have a c from ***concatenate*** ```r mean(c(1,3,6,9,12)) ``` ``` [1] 6.2 ``` Now is working! --- ## 3.3. Look for help One of the strenghts of R is that is widely used and there is a lot of webpages to search for help. Be patience, check if you make a typo and if not copy and paste the error. Reliable sources: - [stackoverflow](https://stackoverflow.com/) - mastodon (before was twitter but the r community move to this platform) Hashtags: #rstats --- class: inverse # Pause .pull-left[ Practice <svg aria-hidden="true" role="img" viewBox="0 0 512 512" style="height:1em;width:1em;vertical-align:-0.125em;margin-left:auto;margin-right:auto;font-size:inherit;fill:#FFFFFF;overflow:visible;position:relative;"><path d="M497.9 142.1l-46.1 46.1c-4.7 4.7-12.3 4.7-17 0l-111-111c-4.7-4.7-4.7-12.3 0-17l46.1-46.1c18.7-18.7 49.1-18.7 67.9 0l60.1 60.1c18.8 18.7 18.8 49.1 0 67.9zM284.2 99.8L21.6 362.4.4 483.9c-2.9 16.4 11.4 30.6 27.8 27.8l121.5-21.3 262.6-262.6c4.7-4.7 4.7-12.3 0-17l-111-111c-4.8-4.7-12.4-4.7-17.1 0zM124.1 339.9c-5.5-5.5-5.5-14.3 0-19.8l154-154c5.5-5.5 14.3-5.5 19.8 0s5.5 14.3 0 19.8l-154 154c-5.5 5.5-14.3 5.5-19.8 0zM88 424h48v36.3l-64.5 11.3-31.1-31.1L51.7 376H88v48z"/></svg> - For each salad 🥗 I need 1.3 cucumbers, how many cucumbers should I buy? ```r Salat<-3 Cucumber<-2 Salat*Cucumber ``` - I also want to make some cakes 🎂 and I need 200 g of sugar. How many grams of sugar do I need for preparing 5 cakes? ```r Cakes<-5 Sugar<-200 ``` ] .pull-right[ Until here: - [rmarkdown](#rmd) - [read files](#read-files) - [basic operations](#basic-operationr) Next part: - [columns and rows](#column-rows) - [count](#count) - [select](#select) - [filter](#filter) - [mutate](#mutate) - [summarise](#sumarise) - [unique](#unique) - [drop_na](#drop) - [join](#join) - [export](#export) - [contact](#out) ] --- name: column-rows class: title-slide, bottom background-image: url(https://images.unsplash.com/photo-1602516095206-3365caa029e4?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=1170&q=80) background-size: cover .pull-right[ # <span style=" font-weight: bold; color: #e5e5e5 !important;border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #003049 !important;" >Data frames</span> ### <span style=" font-weight: bold; color: #e5e5e5 !important;border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #003049 !important;" >Recipe book</span> ] --- ## 4.1. Inspect data frames Load data ```r library(palmerpenguins) ``` ```r penguins<-penguins ``` Check first 5 rows ```r head(penguins,5) ``` Check last 5 rows ```r tail(penguins,5) ``` --- ## 4.3. Rows When you want to inspect specific rows, rows number is writen at the **first** position. ```r (penguins[1,]) ``` Check first 3 rows. <br> The **:** is as "from A to B". ```r (penguins[1:3,]) ``` --- ## 4.4. Columns The columns go on the **second** position. ```r head(penguins[,1]) ``` Another way to do it is with the $ and the column name. ```r head(penguins$species) ``` --- ## 4.5. Column and row Look for a specific value [**row**, **column**] ```r (penguins[1,1]) ``` ``` ## # A tibble: 1 × 1 ## species ## <fct> ## 1 Adelie ``` ```r (penguins[3,2]) ``` ``` ## # A tibble: 1 × 1 ## island ## <fct> ## 1 Torgersen ``` --- name: tidydata class: title-slide, bottom background-image: url(https://images.unsplash.com/reserve/EnF7DhHROS8OMEp2pCkx_Dufer%20food%20overhead%20hig%20res.jpg?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=1178&q=80) background-size: cover .pull-right[ # <span style=" font-weight: bold; color: #e5e5e5 !important;border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #003049 !important;" >Tidy data</span> ### <span style=" font-weight: bold; color: #e5e5e5 !important;border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #003049 !important;" >Ready for cooking</span> ] --- ## 5.1. Tidy data **Data wrangling** is usually the longest and slowest process and you can expect to do this several times. Tidy data is a data structure to facilitate the analyses. There are three interrelated rules which make a dataset tidy: - Each variable must have its own column. - Each observation must have its own row. - Each value must have its own cell. <img src="https://d33wubrfki0l68.cloudfront.net/6f1ddb544fc5c69a2478e444ab8112fb0eea23f8/91adc/images/tidy-1.png" height="200" /> --- ## 5.2. Recomendations - To reduce the time organizing your data, is important to think earlier how are you going to collect and store your data. 🕕 **Why to use tidydata? ** - Many commands will assume that your data is organized. - Is the expected format for statistical analyses. - Its easier to plot organized data. - When sharing the data it would be easier to understand. --- class: inverse # Pause .pull-left[ Practice <svg aria-hidden="true" role="img" viewBox="0 0 512 512" style="height:1em;width:1em;vertical-align:-0.125em;margin-left:auto;margin-right:auto;font-size:inherit;fill:#FFFFFF;overflow:visible;position:relative;"><path d="M497.9 142.1l-46.1 46.1c-4.7 4.7-12.3 4.7-17 0l-111-111c-4.7-4.7-4.7-12.3 0-17l46.1-46.1c18.7-18.7 49.1-18.7 67.9 0l60.1 60.1c18.8 18.7 18.8 49.1 0 67.9zM284.2 99.8L21.6 362.4.4 483.9c-2.9 16.4 11.4 30.6 27.8 27.8l121.5-21.3 262.6-262.6c4.7-4.7 4.7-12.3 0-17l-111-111c-4.8-4.7-12.4-4.7-17.1 0zM124.1 339.9c-5.5-5.5-5.5-14.3 0-19.8l154-154c5.5-5.5 14.3-5.5 19.8 0s5.5 14.3 0 19.8l-154 154c-5.5 5.5-14.3 5.5-19.8 0zM88 424h48v36.3l-64.5 11.3-31.1-31.1L51.7 376H88v48z"/></svg> - Calculate the range of the body mass of the penguins. ```r range(penguins$body_mass_g, na.rm=TRUE) ``` - Calculate the mean of the body mass of the penguins. ```r mean(penguins$body_mass_g, na.rm=TRUE) ``` Note that **na.rm allows you to ignore NAs** <img src="https://raw.githubusercontent.com/allisonhorst/palmerpenguins/master/man/figures/lter_penguins.png" height="90" /> ] .pull-right[ Until here: - [rmarkdown](#rmd) - [read files](#read-files) - [basic operations](#basic-operationr) Next part: - [columns and rows](#column-rows) - [count](#count) - [select](#select) - [filter](#filter) - [mutate](#mutate) - [summarise](#sumarise) - [unique](#unique) - [drop_na](#drop) - [join](#join) - [export](#export) - [contact](#out) ] --- name: #tidyverse class: title-slide, bottom background-image: url(https://images.unsplash.com/photo-1531932755987-f95a88affea5?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=1170&q=80) background-size: cover .pull-right[ # <span style=" font-weight: bold; color: #e5e5e5 !important;border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #003049 !important;" >Functions</span> ### <span style=" font-weight: bold; color: #e5e5e5 !important;border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #003049 !important;" >Cooking</span> ] --- ## 6. Tidyverse There are many ways to organize and wrangle your data. Here we will cover those from the **tidyverse**. ```r library(tidyverse) ``` Tidyverse include many packages, a lot of them are specific for inspect and **wrangle** your data. .center[ <img src="https://tidyverse.tidyverse.org/articles/tidyverse-logo.png" height="300" /> ] --- ## 6.1. Pipe A **pipe** is an argument we will use very often. The **pipe** allows to chain several functions. In your keyboard: strg+alt+M ```r %>% ``` --- name: count ## 6.2. count() This functions lets you quickly count the unique values of one or more variables Load library ```r library(tidyverse) ``` Sample size? ```r penguins %>% * count() ``` Sample size per species? ```r penguins %>% * count(species) ``` Per island and per species? ```r penguins %>% * count(island,species) ``` --- name: distinct ## 6.3. unique() or distinct() Allows you to see unique values or factors. Using base R ```r unique(penguins$species) ``` Using tidyverse ```r penguins %>% * distinct(species) ``` --- name: select ## 6.4. select() Select variables in a data frame .pull-left[ Select one column ```r penguins %>% * select(species) ``` Remove one column using " **-** " ```r penguins %>% * select(-sex) ``` Select all columns expect this one using " **!** " ```r penguins %>% * select(!sex) ``` ] .pull-right[ Select columns in between using "**:** " ```r penguins %>% * select(bill_length_mm:body_mass_g) ``` Using the final letter of the string ```r penguins %>% * select(ends_with("mm")) ``` Using the first letters of the string ```r penguins %>% * select(starts_with("bill")) ``` ] --- name: filter ## 6.5. filter() The filter() function is used to subset a data frame, retaining all rows that satisfy your conditions. There are many functions and operators, some useful expressions are: - The symbol **==** means 'same as' - The symbol **!=** means 'not the same as' - The symbol **>** means 'larger than' - The symbol **<** means 'smaller than' - The symbol **>=** means 'larger or same as' - The symbol **<=** means 'smaller or same as' - The symbol **&** means 'and' - The symbol **|** means 'or' --- ## 6.5. filter(==) - The symbol **==** means 'same as' ```r penguins %>% * filter(sex == 'female') ``` **Note** variables are without quotes and observations in quotes. -- Is there actually something different in the object at your environment? -- To change the object we need to create a new data frame. ```r female_penguins<-penguins %>% * filter(sex == 'female') ``` --- ## 6.5. filter(<=) - The symbol **<=** means 'smaller or same as' ```r penguins %>% * filter(bill_lenght_mm <= 39.1) ``` - The symbol **>=** means 'larger or same as' ```r penguins %>% * filter(bill_length_mm >= 39.1) ``` - The symbol **&** means 'and' ```r penguins %>% * filter(island == 'Biscoe' & species =='Adelie') ``` --- name: mutate ## 6.6. mutate() mutate() creates new columns that are functions of existing variables. It can also modify (if the name is the same as an existing column) and delete columns (by setting their value to NULL). ```r penguins<-penguins %>% * mutate(body_mass_kg = body_mass_g / 1000) ``` --- name: summarise ## 6.7. group_by() y summarise() group_by() lets you select an specific column for grouping the factors within summarise() can be used to use specific operations for each factor defined in the group_by ```r penguins %>% * group_by(year) %>% * summarise(mean_bill_length=mean(bill_length_mm)) ``` ``` ## # A tibble: 3 × 2 ## year mean_bill_length ## <int> <dbl> ## 1 2007 NA ## 2 2008 43.5 ## 3 2009 NA ``` --- name: drop ## 6.8. drop_na This functions allows you to ignore or remove NAs ```r penguins %>% * drop_na(bill_length_mm) ``` Another option is to remove the nas ```r clean_penguins <- penguins %>% * filter(!is.na(bill_length_mm)) ``` Example of using drop_na with other functions ```r penguins %>% group_by(year) %>% * drop_na(bill_length_mm) %>% summarise(mean_bill_length=mean(bill_length_mm)) ``` --- ## 6.9. lubridate We often use date and time, so lets try with an example using this data type. The package **lubridate** provides tools that make it easier to parse and manipulate dates. ```r library(lubridate) ``` ```r ymd_hms("2010-12-13 15:30:30") ``` You can **extract** some elements from dates and times ```r ymd_hms("2010-12-13 15:30:30") %>% month() ``` ``` ## [1] 12 ``` --- ## 6.9. lubridate Lets try with this data frame. ```r my_timestamps<-data.frame(timestamp=c("2010-12-13 13:30:30","2010-12-13 14:30:30","2010-12-13 15:30:30","2010-12-13 16:30:30","2010-12-13 17:30:30","2010-12-13 18:30:30","2010-12-13 19:30:30","2010-12-13 20:30:30")) ``` Using mutate we can separate elements form the date and time ```r my_timestamps %>% mutate( my_hours = hour(timestamp), my_minutes = minute(timestamp), my_seconds = second(timestamp) ) ``` --- class: inverse # Pause .pull-left[ Practice <svg aria-hidden="true" role="img" viewBox="0 0 512 512" style="height:1em;width:1em;vertical-align:-0.125em;margin-left:auto;margin-right:auto;font-size:inherit;fill:#FFFFFF;overflow:visible;position:relative;"><path d="M497.9 142.1l-46.1 46.1c-4.7 4.7-12.3 4.7-17 0l-111-111c-4.7-4.7-4.7-12.3 0-17l46.1-46.1c18.7-18.7 49.1-18.7 67.9 0l60.1 60.1c18.8 18.7 18.8 49.1 0 67.9zM284.2 99.8L21.6 362.4.4 483.9c-2.9 16.4 11.4 30.6 27.8 27.8l121.5-21.3 262.6-262.6c4.7-4.7 4.7-12.3 0-17l-111-111c-4.8-4.7-12.4-4.7-17.1 0zM124.1 339.9c-5.5-5.5-5.5-14.3 0-19.8l154-154c5.5-5.5 14.3-5.5 19.8 0s5.5 14.3 0 19.8l-154 154c-5.5 5.5-14.3 5.5-19.8 0zM88 424h48v36.3l-64.5 11.3-31.1-31.1L51.7 376H88v48z"/></svg> ```r penguins %>% count() ``` ```r penguins %>% select(especie) ``` ```r penguins %>% group_by(species,sex) %>% drop_na(body_mass_g,sex)%>% summarise(mean_body_mass_g = mean(body_mass_g), n = n())%>% mutate(mean_body_mass_kg = mean_body_mass_g / 1000) ``` ] .pull-right[ Until here: - [rmarkdown](#rmd) - [read files](#read-files) - [basic operations](#basic-operationr) - [columns and rows](#column-rows) - [count](#count) - [distinct](#distinct) - [select](#select) - [filter](#filter) - [mutate](#mutate) - [summarise](#sumarise) - [drop_na](#drop) Next part: - [join](#join) - [export](#export) - [contact](#out) ] --- name: join class: title-slide, bottom background-image: url(https://images.unsplash.com/photo-1638792958866-9b3f787ec709?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=1170&q=80) background-size: cover .pull-right[ # <span style=" font-weight: bold; color: #e5e5e5 !important;border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #003049 !important;" >Join</span> ### <span style=" font-weight: bold; color: #e5e5e5 !important;border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #003049 !important;" >Mixing ingredients</span> ] --- ## 7. Mutating joins Mutating joins add columns from y to x, matching observations based on the keys. There are four mutating joins: the inner join, and the three outer joins. Lets create a new data set. ```r bird_id<-c("ID01","ID02","ID03","ID04","ID05", "ID06","ID07","ID08","ID09","ID10") bird_mass<-c(1.5,2.0,3.5,4.1,2.6,3.7,8.9,2.5,6.3,1.0) bird_gps<-c(50010,50020,50035,50001,50006,50003,50008,50002,50003,50001) ``` We might have two data sets .pull-left[ On one hand, the measurement data... ```r bird_measurements<- data.frame(bird_id, bird_mass) ``` ] .pull-right[ ... on the other, field data. ```r bird_tracking <- data.frame(bird_id, bird_gps) ``` ] --- ## 7.1. left_join() To join them we can use the function **left_join()** But it is important to have a **key** to match the observations ```r bird_joined<-left_join(bird_measurements, bird_tracking, * by = "bird_id") ``` left_join() uses the **key** to join the data frames <br> <img src="https://raw.githubusercontent.com/MiriamLL/Curso_CIAD/main/Figuras/left-join.gif" height="200" /> [Other options](https://www.garrickadenbuie.com/project/tidyexplain/) --- ## 7.2. pivot_longer Sometimes the data are not organized in a way that each observation has a row and a column. This is very common, particularly in the lab or fieldwork because is not the same how we write in a notebook than in the computer. To re-organized, we can use the function **pivot_longer**. <img src="https://github.com/MiriamLL/R_intro/blob/master/Images/201longer.png?raw=true" height="350" /> --- ## 7.2. pivot_longer Lets imagine we have data from five species and their number of locations among three different years. ```r bird_id<-c("ID01","ID02","ID03","ID04","ID05", "ID06","ID07","ID08","ID09","ID10") year_2010<-c(5,4,5,6,7,3,2,1,9,10) year_2011<-c(3,2,1,9,4,5,6,7,3,2) year_2012<-c(6,2,3,7,8,2,1,9,4,5) ``` New data frame ```r bird_nlocs<-data.frame(bird_id,year_2010,year_2011,year_2012) ``` ```r head(bird_nlocs,5) ``` ``` ## bird_id year_2010 year_2011 year_2012 ## 1 ID01 5 3 6 ## 2 ID02 4 2 2 ## 3 ID03 5 1 3 ## 4 ID04 6 9 7 ## 5 ID05 7 4 8 ``` --- ## 7.2. pivot_longer pivot_longer "lengthens" data, increasing the number of rows and decreasing the number of columns. ```r bird_long <- bird_nlocs %>% pivot_longer(c(year_2010,year_2011,year_2012), names_to = "year", values_to = "nlocs" ) ``` ```r head(bird_long,5) ``` ``` ## # A tibble: 5 × 3 ## bird_id year nlocs ## <chr> <chr> <dbl> ## 1 ID01 year_2010 5 ## 2 ID01 year_2011 3 ## 3 ID01 year_2012 6 ## 4 ID02 year_2010 4 ## 5 ID02 year_2011 2 ``` --- ## 7.3. pivot_wider The opposite will be to separate the columns. pivot_wider() "widens" data, increasing the number of columns and decreasing the number of rows. <img src="https://github.com/MiriamLL/R_intro/blob/master/Images/201wider.png?raw=true" height="350" /> --- ## 7.3. pivot_wider The most important arguments are **names_from** which are going to be the names of the columns created after (often the column with factors) and **values_from** is the the name of the column with the values (often the columns with numbers) ```r bird_wide<-bird_long %>% pivot_wider(names_from = year, values_from = nlocs) ``` --- name: paste ## 7.4. paste or unite The argument **paste** or **paste0** from base R allows you to paste together multiple columns ```r bird_long$unique_id<-paste0(bird_long$bird_id,'_',bird_long$year) ``` The argument **unite** is similar, but lets you to paste together multiple columns into one. ```r bird_long<-bird_long %>% * unite(col = unique_id2, c("bird_id", "year"), sep = "_", remove=FALSE) ``` **Note** it will get rid of the original column, so if you don't want to eliminate the original column add **remove = FALSE.** --- ## 7.5. separate The argument **separate** allows you to separate the values from one column into two columns. ```r bird_long %>% * separate(col = unique_id, into = c("id", "text","year"), sep = "_") ``` **Note** it will get rid of the original column, so if you don't want to eliminate the original column add **remove = FALSE.** ```r bird_long<-bird_long %>% * separate(col = unique_id, into = c("id", "text","year"), sep = "_", * remove = FALSE) ``` --- ## 7.6. rename The argument **rename** allows to change the name of one or several columns. The new name is written first and the old name comes after. An example changing the name of one column ```r bird_long %>% * rename(unique_identifier = unique_id2) ``` --- ## 7.7. relocate The argument **relocate** allows you to reorganize your columns and keeping just those that you are interested on. ```r bird_long %>% * relocate(bird_id,year,nlocs) ``` Using this argument together with select you can keep only the columns of interest. ```r bird_long %>% select(bird_id,year,nlocs)%>% * relocate(bird_id,year,nlocs) ``` --- ## 7.8. keep learning Use the dplyr [cheatSheet](https://dplyr.tidyverse.org/). Try the [exercises](https://allisonhorst.shinyapps.io/edge-of-the-tidyverse/#section-wrangling-in-dplyr) from Allison horst. Cheatsheets Help > Cheat sheet > Data transformation with dplyr <img src="https://raw.githubusercontent.com/MiriamLL/Curso_CIAD/main/Figuras/dplyrcheatsheet.jpg" height="300" /> --- class: inverse # Pause .pull-left[ Practice <svg aria-hidden="true" role="img" viewBox="0 0 512 512" style="height:1em;width:1em;vertical-align:-0.125em;margin-left:auto;margin-right:auto;font-size:inherit;fill:#FFFFFF;overflow:visible;position:relative;"><path d="M497.9 142.1l-46.1 46.1c-4.7 4.7-12.3 4.7-17 0l-111-111c-4.7-4.7-4.7-12.3 0-17l46.1-46.1c18.7-18.7 49.1-18.7 67.9 0l60.1 60.1c18.8 18.7 18.8 49.1 0 67.9zM284.2 99.8L21.6 362.4.4 483.9c-2.9 16.4 11.4 30.6 27.8 27.8l121.5-21.3 262.6-262.6c4.7-4.7 4.7-12.3 0-17l-111-111c-4.8-4.7-12.4-4.7-17.1 0zM124.1 339.9c-5.5-5.5-5.5-14.3 0-19.8l154-154c5.5-5.5 14.3-5.5 19.8 0s5.5 14.3 0 19.8l-154 154c-5.5 5.5-14.3 5.5-19.8 0zM88 424h48v36.3l-64.5 11.3-31.1-31.1L51.7 376H88v48z"/></svg> ```r left_join(bird_measurements, bird_tracking, by = "bird_id") ``` ```r bird_long <- bird_nlocs %>% pivot_longer(c(year_2010,year_2011,year_2012), names_to = "year", values_to = "nlocs" ) ``` ```r bird_wide<-bird_long %>% pivot_wider(names_from = year, values_from = nlocs) ``` ] .pull-right[ Until here: - [rmarkdown](#rmd) - [read files](#read-files) - [basic operations](#basic-operationr) - [count](#count) - [distinct](#distinct) - [select](#select) - [filter](#filter) - [mutate](#mutate) - [summarise](#sumarise) - [drop_na](#drop) - [join](#join) Next part: - [export](#export) - [contact](#out) ] --- name: export class: title-slide, bottom background-image: url(https://images.unsplash.com/photo-1630881895380-8993e2d5c45b?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=1631&q=80) background-size: cover .pull-right[ # <span style=" font-weight: bold; color: #e5e5e5 !important;border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #003049 !important;" >Export</span> ### <span style=" font-weight: bold; color: #e5e5e5 !important;border-radius: 4px; padding-right: 4px; padding-left: 4px; background-color: #003049 !important;" >Storing in order</span> ] --- # 8. Export Similar to the read files arguments (read_csv), each one has their equivalent to write. - write_csv() - write_csv2() - write_tsv() - write_delim() --- class: inverse # Pause Practice <svg aria-hidden="true" role="img" viewBox="0 0 512 512" style="height:1em;width:1em;vertical-align:-0.125em;margin-left:auto;margin-right:auto;font-size:inherit;fill:#FFFFFF;overflow:visible;position:relative;"><path d="M497.9 142.1l-46.1 46.1c-4.7 4.7-12.3 4.7-17 0l-111-111c-4.7-4.7-4.7-12.3 0-17l46.1-46.1c18.7-18.7 49.1-18.7 67.9 0l60.1 60.1c18.8 18.7 18.8 49.1 0 67.9zM284.2 99.8L21.6 362.4.4 483.9c-2.9 16.4 11.4 30.6 27.8 27.8l121.5-21.3 262.6-262.6c4.7-4.7 4.7-12.3 0-17l-111-111c-4.8-4.7-12.4-4.7-17.1 0zM124.1 339.9c-5.5-5.5-5.5-14.3 0-19.8l154-154c5.5-5.5 14.3-5.5 19.8 0s5.5 14.3 0 19.8l-154 154c-5.5 5.5-14.3 5.5-19.8 0zM88 424h48v36.3l-64.5 11.3-31.1-31.1L51.7 376H88v48z"/></svg> Define a folder ```r library(here) ResultsFolder<-here() ``` Export to csv ```r write_csv( bird_joined, file =paste0(ResultsFolder,'/bird_joined.csv')) ``` --- name: out class: title-slide background-image: url(https://images.unsplash.com/photo-1587246574087-0b56fabf9861?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxzZWFyY2h8MzExfHxob3JuZWFuZG98ZW58MHx8MHx8&auto=format&fit=crop&w=500&q=60) background-size: cover ### Back to - [rmarkdown](#rmd) - [read files](#read-files) - [basic operations](#basic-operationr) - [columns and rows](#column-rows) - [distinct](#distinct) - [count](#count) - [select](#select) - [filter](#filter) - [mutate](#mutate) - [summarise](#sumarise) - [drop_na](#drop) - [join](#join) - [export](#export) .right[ <br> <br> <br> This materials are free of use <br> Download the presentation here: [<svg aria-hidden="true" role="img" viewBox="0 0 512 512" style="height:1em;width:1em;vertical-align:-0.125em;margin-left:auto;margin-right:auto;font-size:inherit;fill:#f2cc8f;overflow:visible;position:relative;"><path d="M432,320H400a16,16,0,0,0-16,16V448H64V128H208a16,16,0,0,0,16-16V80a16,16,0,0,0-16-16H48A48,48,0,0,0,0,112V464a48,48,0,0,0,48,48H400a48,48,0,0,0,48-48V336A16,16,0,0,0,432,320ZM488,0h-128c-21.37,0-32.05,25.91-17,41l35.73,35.73L135,320.37a24,24,0,0,0,0,34L157.67,377a24,24,0,0,0,34,0L435.28,133.32,471,169c15,15,41,4.5,41-17V24A24,24,0,0,0,488,0Z"/></svg>github](https://github.com/MiriamLL/R_intro) and [<svg aria-hidden="true" role="img" viewBox="0 0 512 512" style="height:1em;width:1em;vertical-align:-0.125em;margin-left:auto;margin-right:auto;font-size:inherit;fill:#f2cc8f;overflow:visible;position:relative;"><path d="M432,320H400a16,16,0,0,0-16,16V448H64V128H208a16,16,0,0,0,16-16V80a16,16,0,0,0-16-16H48A48,48,0,0,0,0,112V464a48,48,0,0,0,48,48H400a48,48,0,0,0,48-48V336A16,16,0,0,0,432,320ZM488,0h-128c-21.37,0-32.05,25.91-17,41l35.73,35.73L135,320.37a24,24,0,0,0,0,34L157.67,377a24,24,0,0,0,34,0L435.28,133.32,471,169c15,15,41,4.5,41-17V24A24,24,0,0,0,488,0Z"/></svg>webpage](https://www.miriam-lerma.com/posts/2023-05-08-data-wrangling/) ] .center[ <h3><svg aria-hidden="true" role="img" viewBox="0 0 576 512" style="height:1em;width:1.12em;vertical-align:-0.125em;margin-left:auto;margin-right:auto;font-size:inherit;fill:#e9c46a;overflow:visible;position:relative;"><path d="M280.37 148.26L96 300.11V464a16 16 0 0 0 16 16l112.06-.29a16 16 0 0 0 15.92-16V368a16 16 0 0 1 16-16h64a16 16 0 0 1 16 16v95.64a16 16 0 0 0 16 16.05L464 480a16 16 0 0 0 16-16V300L295.67 148.26a12.19 12.19 0 0 0-15.3 0zM571.6 251.47L488 182.56V44.05a12 12 0 0 0-12-12h-56a12 12 0 0 0-12 12v72.61L318.47 43a48 48 0 0 0-61 0L4.34 251.47a12 12 0 0 0-1.6 16.9l25.5 31A12 12 0 0 0 45.15 301l235.22-193.74a12.19 12.19 0 0 1 15.3 0L530.9 301a12 12 0 0 0 16.9-1.6l25.5-31a12 12 0 0 0-1.7-16.93z"/></svg>[Home ](https://www.miriam-lerma.com/teaching.html) ] <br>